

存储引擎的区别
-
MyISAM引擎每张表中存放了一个meta信息,里面包含了row_count属性,内存和文件中各有一份,内存的count变量值通过读取文件中的count值来进行初始化。[1]但是如果带有where条件,还是必须得进行表扫描
-
InnoDB引擎执行count()的时候,需要把数据一行行从引擎里面取出来进行统计。
下面我们介绍InnoDB中的count()。
count中的一致性视图
InnoDB中为何不像MyISAM那样维护一个row_count变量呢?
前面 洞悉MySQL底层架构:游走在缓冲与磁盘之间 一文我们了解到,InnoDB为了实现事务,是需要MVCC支持的。MVCC的关键是一致性视图。一个事务开启瞬间,所有活跃的事务(未提交)构成了一个视图数组,InnoDB就是通过这个视图数组来判断行数据是否需要undo到指定的版本。
如下图,假设执行count的时候,一致性视图得到当前事务能够取到的最大事务ID DATA_TRX_ID=1002,那么行记录中事务ID超过1002都都要通过undo log进行版本回退,最终才能得出最终哪些行记录是当前事务需要统计的:
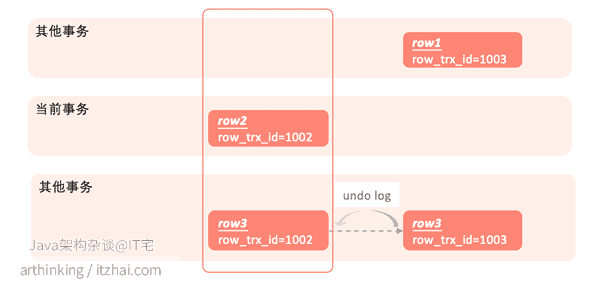
row1是其他事务新插入的记录,当前事务不应该算进去。所以最终得出,当前事务应该统计row2,row3。
执行count会影响其他页面buffer pool的命中率吗?
我们知道buffer pool中的LRU算法是是经过改进的,默认情况下,旧子列表(old区)占3/8,count加载的页面一直往旧子列表中插入,在旧子列表中淘汰,不会晋升到新子列表中。所以不会影响其他页面buffer pool的命中率。
count(主键)
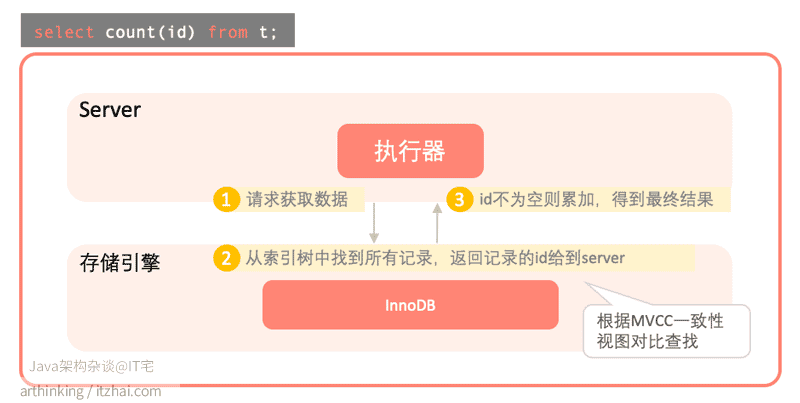
count(主键)执行流程如下:
- 执行器请求存储引擎获取数据;
- 为了保证扫描数据量更少,存储引擎找到最小的那颗索引树获取所有记录,返回记录的id给到server。返回记录之前会进行MVCC及其可见性的判断,只返回当前事务可见的数据;
- server获取到记录之后,判断id如果不为空,则累加到结果记录中。
count(1)
count(1)与count(主键)执行流程基本一致,区别在于,针对查询出的每一条记录,不会取记录中的值,而是**直接返回一个"1"**用于统计累加。统计了所有的行。
count(字段)
与count(主键)类似,会筛选非空的字段进行统计。如果字段没有添加索引,那么会扫描聚集索引树,导致扫描的数据页会比较多,效率相对慢点。
count(*)
count(*)不会取记录的值,与count(1)类似。
执行效率对比:count(字段) < count(主键) < count(1)

