

1、完全走索引
我们给t30加一个索引:
1 | alter table t30 add index idx_c(c); |
执行以下group bysql:
1 | select c, count(*) from t30 group by c; |
执行计划如下:

发现这里只用到了索引,原因是idx_c索引本身就是按照c排序好的,那么直接顺序扫描idx_c索引,可以直接统计到每一个c值有多少条记录,无需做其他的统计了。
2、临时表
现在我们把刚刚的idx_c索引给删掉,执行以下sql:
1 | select c, count(*) from t30 group by c order by null; |
为了避免排序,所以我们这里添加了 order by null,表示不排序。
执行计划如下:

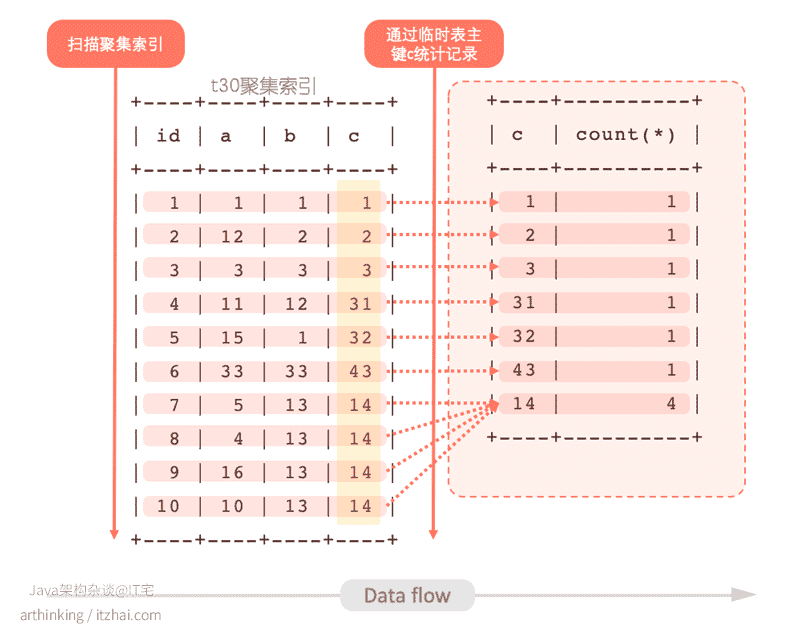
可以发现,这里用到了内存临时表。其执行流程如下:
- 扫描t30聚集索引;
- 建立一个临时表,以字段c为主键,依次把扫描t30的记录通过临时表的字段c进行累加;
- 把最后累加得到的临时表返回给客户端。
3、临时表 + 排序
如果我们把上一步的order by null去掉,默认情况下,group by的结果是会通过c字段排序的。我们看看其执行计划:

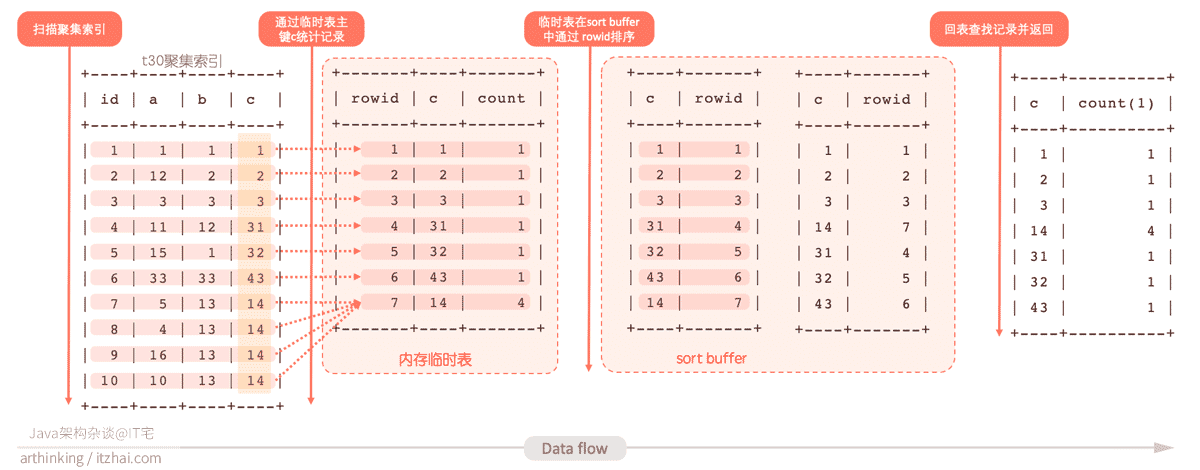
可以发现,这里除了用到临时表,还用到了排序。
我们进一步看看其执行的OPTIMIZER_TRACE日志:
1 | "steps": [ |
通过日志也可以发现,这里用到了中间临时表,由于没有limit限制条数,这里没有用到优先级队列排序,这里的排序模式为sort_key, rowid。其执行流程如下:
- 扫描t30聚集索引;
- 建立一个临时表,以字段c为主键,依次把扫描t30的记录通过临时表的字段c进行累加;
- 把得到的临时表放入sort buffer进行排序,这里通过rowid进行排序;
- 通过排序好的rowid回临时表查找需要的字段,返回给客户端。
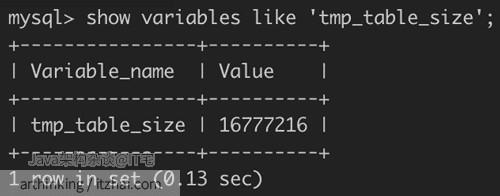
临时表是存放在磁盘还是内存?
tmp_table_size 参数用于设置内存临时表的大小,如果临时表超过这个大小,那么会转为磁盘临时表:
可以通过以下sql设置当前session中的内存临时表大小:SET tmp_table_size = 102400;
4、直接排序
查看官方文档的 SELECT Statement[1],可以发现SELECT后面可以使用许多修饰符来影响SQL的执行效果:
1 | SELECT |
这里我们重点关注下这两个:
SQL_BIG_RESULT:可以在包含group by 和distinct的SQL中使用,提醒优化器查询数据量很大,这个时候MySQL会直接选用磁盘临时表取代内存临时表,避免执行过程中发现内存不足才转为磁盘临时表。这个时候更倾向于使用排序取代二维临时表统计结果。后面我们会演示这样的案例;SQL_SMALL_RESULT:可以在包含group by 和distinct的SQL中使用,提醒优化器数据量很小,提醒优化器直接选用内存临时表,这样会通过临时表统计,而不是排序。
当然,在平时工作中,不是特定的调优场景,以上两个修饰符还是比较少用到的。
接下来我们就通过例子来说明下使用了SQL_BIG_RESULT修饰符的SQL执行流程。
有如下SQL:
1 | select SQL_BIG_RESULT c, count(*) from t30 group by c; |
执行计划如下:

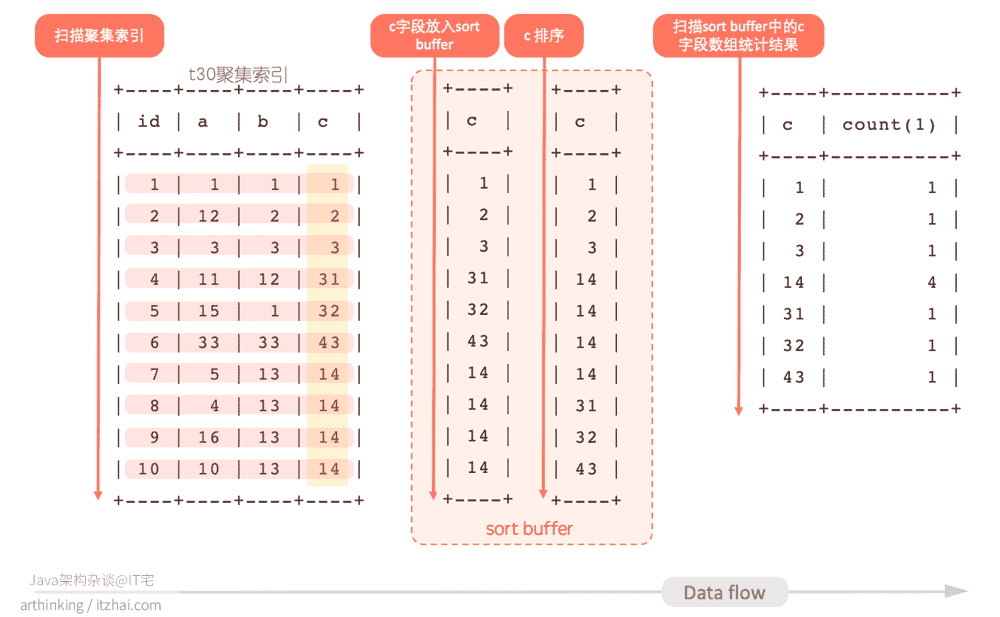
可以发现,这里只用到了排序,没有用到索引或者临时表。这里用到了SQL_BIG_RESULT修饰符,告诉优化器group by的数据量很大,直接选用磁盘临时表,但磁盘临时表存储效率不高,最终优化器使用数组排序的方式来完成这个查询。(当然,这个例子实际的结果集并不大,只是作为演示用)
其执行结果如下:
- 扫描t30表,逐行的把c字段放入sort buffer;
- 在sort buffer中对c字段进行排序,得到一个排序好的c数组;
- 遍历这个排序好的c数组,统计结果并输出。
5、group by 优化建议
- 尽量让group by走索引,能最大程度的提高效率;
- 如果group by结果不需要排序,那么可以加上
order by null,避免进行排序; - 如果group by的数据量很大,可以使用
SQL_BIG_RESULT修饰符,提醒优化器应该使用排序算法得到group的结果。

