

当我们的缓存空间不够的时候,还想加载新的数据怎么办呢?要么就加载不了了,要么就得删掉一些使用率比较低的缓存,腾出空间来加载新的数据到缓存中。
那么,我们的缓存应该设置多大比较合理?
1、缓存应该设置多大?
Wired杂志的Chris Anderson,创造了术语“长尾”来指代电子商务系统中少量的商品可以构成大部分的销售额,少量的博客可以获得大部分的点击量,还有一些是不太受欢迎的“长尾巴”,如下图所示(来源 Hello, Ehcache[1] ):
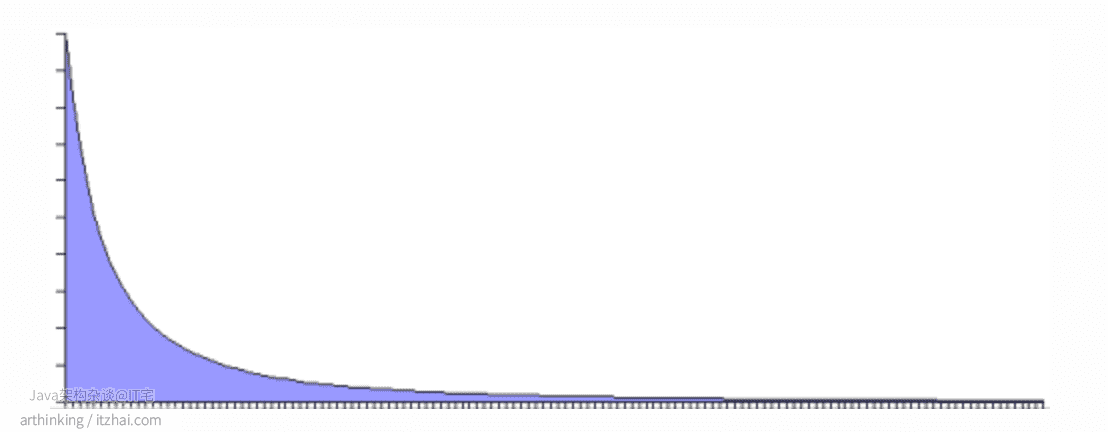
长尾是幂律分布(Power Law)的一个示例,还有帕累托分布或八二法则(80:20 rule)。
基于八二法则,我们可以分析缓存使用效率的一般规律:20% 的对象在 80% 的时间内被使用,剩余的数据量虽然很大,但是只有20%的访问量。
我们可以基于八二法则,加上对业务的访问特征评估,来预估要分配的缓存的大小。
一旦确定下来之后,就可以到redis.conf中进行配置了:
1 | # maxmemory <bytes> |
2、缓存何时淘汰?
当Redis占用的内存超过了设置的maxmemory的值的时,Redis将启用缓存淘汰策略来删除缓存中的key,设置淘汰策略配置参数:
1 | maxmemory-policy noeviction # 默认的淘汰策略,不删除任何key,内存不足的时候写入返回错误 |
当内存到达上限之后,Redis会选择什么数据进行淘汰呢?这个跟设置的淘汰策略有关。可选的淘汰策略:
volatile,只针对设置了过期时间的key的淘汰策略volatile-lru:使用近似 LRU(Least Recently Used, 最近最少使用) 驱逐,淘汰带有过期时间的键值对volatile-lfu:使用近似的 LFU(Least Frequently Used, 最不经常使用) 驱逐,淘汰带有过期时间的键值对volatile-random:随机驱除,淘汰带有过期时间的键值对volatile-ttl:删除过期时间最近的键值对(最小TTL)
allkeys,对所有范围的key有效的淘汰策略allkeys-lru:使用近似 LRU 驱逐,淘汰任何键值对allkeys-lfu:使用近似 LFU 驱逐,淘汰任何键值对allkeys-random:删除随机键值对
noeviction:不要驱逐任何东西,只是在写操作时返回一个错误。
在内存不足的时候,如果一个键值对被删除策略选中了,即使还没有过期,也会被删掉。
LRU, Least Recently Used, 最近最少使用淘汰算法,淘汰最长时间没有被使用的缓存;
LFU, Least Frequently Used, 最不经常使用淘汰算法,淘汰一段时间内,使用次数最少的缓存。
注意:使用上述任何一种策略,当没有合适的键可以驱逐时,Redis 将在需要更多内存的写操作时返回错误。
出于效率的考虑,LRU、LFU 和 volatile-ttl 都不是精确算法,而是使用近似随机算法实现的。
Redis中的LRU,LFU算法是如何实现的?我应该是用哪种策略?
Redis中的LRU算法
为了实现一个LRU,我们需要一个链表,每访问了链表中的某个元素之后,该元素都需要往链表表头移动。
使用链表存储的缺点:
- 想象一下,假如Redis的key也放入一个这样的链表,大量的key同时被访问,导致链表内部频繁移动,这极大的降低了Redis的访问性能;
- 我们需要存储链表的前继指针prev,后继指针next,至少占用16个字节,消耗空间比较大。
为此,Redis并没有按照链表的方式实现LRU算法。
我们在介绍RedisObject的时候,有提到其中有一个lru字段:
1 | typedef struct redisObject { |
该字段用于记录最近一次的访问时钟。这个字段只使用改了24位(3个字节)来存储。
Redis通过随机采样获取取一组数据,放入驱逐池(实际上是一个链表)中,池中的key按照空闲时间从小到大排列,最终从池末尾选一个键进行删除,从而把lru值最小的数据淘汰掉;不断重复这个过程,直到内存使用量低于限制。
Redis中的LRU算法会有什么问题?
Redis中每次读取新的数据到内存中,都会更新该缓存的lru字段,如果我们一次性读取了大量不会再被读取的数据到缓存中,而此时刚好要执行缓存数据淘汰,那么这些一次性的数据就会把其他lru字段比较小,但是使用很频繁的缓存给淘汰掉了,这也称为缓存污染。
举个例子,有家中餐店,里面有8个顾客正在吃饭,这个时候,突然来了四个不得不接待的顾客,需要腾出4个位置,该如何选择呢?
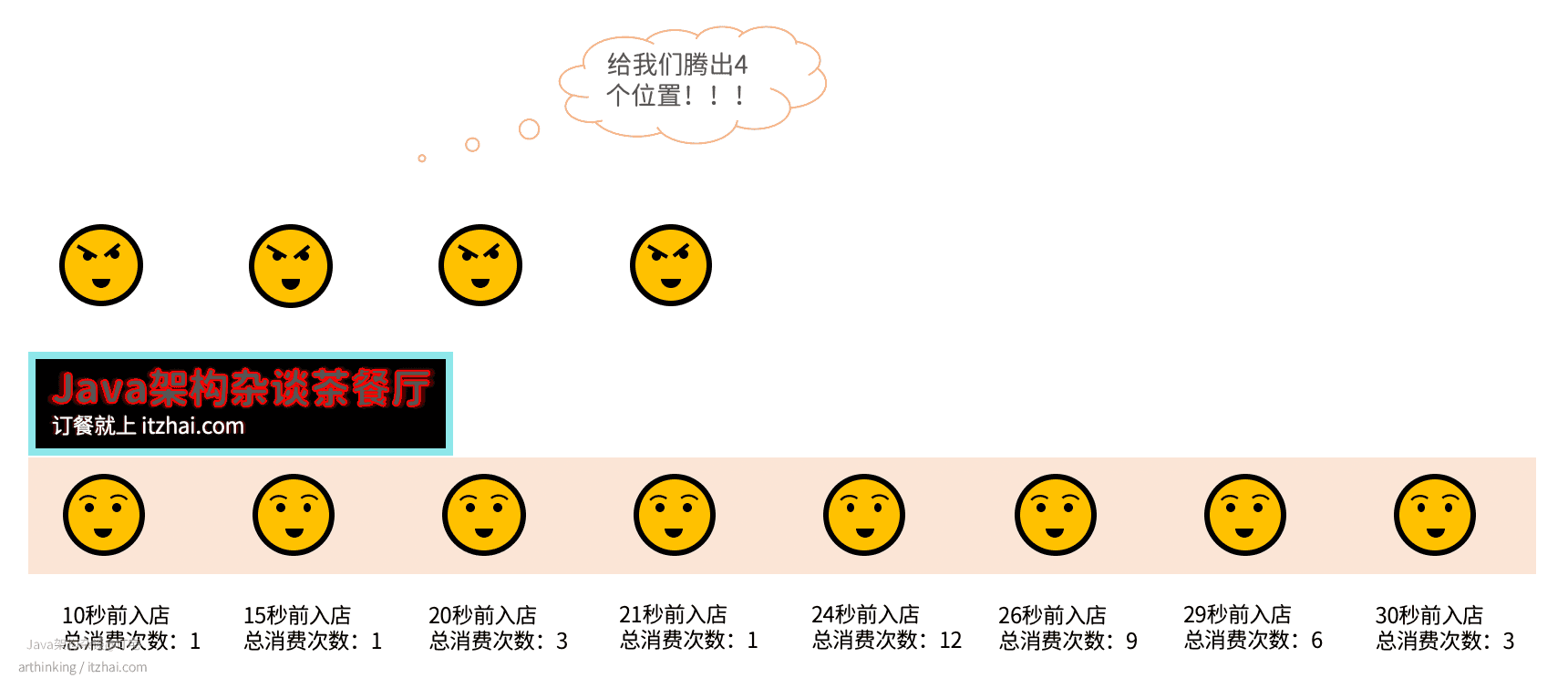
在Redis中,则会直接把入店时间最久的4个给淘汰掉,可以发现,我们直接把熟客给打发走了,最终导致丢失了常客,得不偿失:
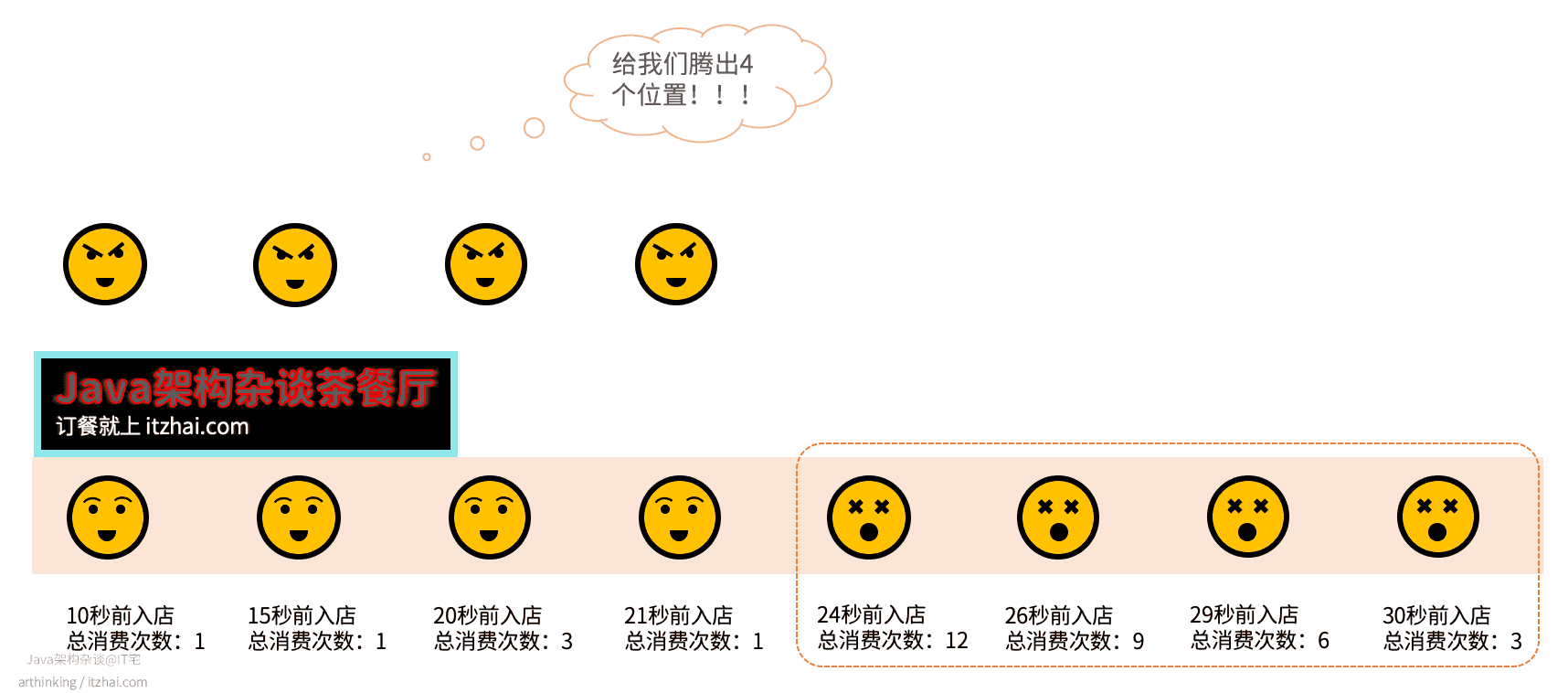
为了避免LRU队列的缓存污染问题,在Redis 4.0版本开始,提供了一种新的淘汰策略:LFU,下面简单介绍下。
MySQL如何避免LRU队列被冲刷掉?
MySQL也会有类似的全表扫描导致读取一次性的数据冲刷LRU队列的问题。为此,MySQL实现了一种改进版本的LRU算法,避免全表扫描导致LRU队列中的最近频繁使用的数据被冲刷掉。参考:洞悉MySQL底层架构:游走在缓冲与磁盘之间#3.1.1、缓冲池LRU算法[2]
Redis中的LFU算法
在Redis中LFU策略中,会记录每个键值对的访问次数。当进行淘汰数据的时候,首先会把访问次数最低的数据淘汰出缓存,如果淘汰过程中发现两个键值对访问次数一样,那么再把上一次访问时间更久的键值对给淘汰掉:
访问次数低的先淘汰,次数相同则淘汰lru比较小的。
举个例子,还是那个Java架构杂谈茶餐厅,来了4个得罪不起的顾客,需要腾出4个位置,使用了Redis的LFU算法之后,则是腾出这四个:
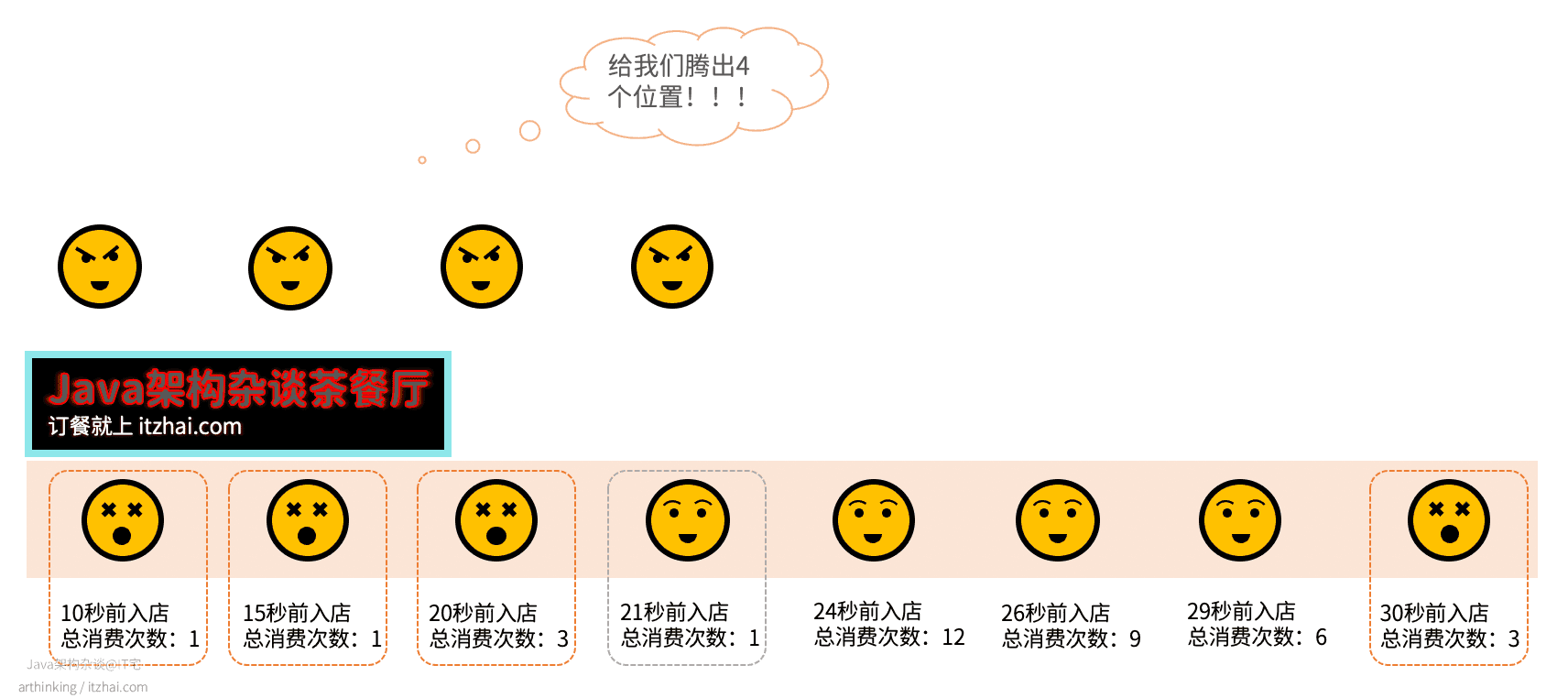
可以发现,我们优先把总消费次数比较低的顾客给打发走了,3号和8号顾客总消费次数一样,所以我们把那个进店比较久的8号顾客打发走了。
这样就可以最大程度的优先保证了熟客的用餐体验,至于我们在3号和8号顾客之间,选择打发走8号顾客,是因为可能8号顾客只点了几个咖喱鱼蛋,30秒狼吞虎咽就吃完了呢?也不是没可能,所以就让他先出去了。
LFU算法如何记录访问次数?
Redis中的LFU算法是基于LRU算法改进的,而Redis 的惊人之处在于它只是重用了 24 位 LRU 时钟空间,也就是 3 个八位字节中存储了访问计数器和最近一次衰减时间。
在key超过一定时间没被访问之后,Redis就会衰减counter的值,这是必要的,否则计数器将收敛到 255 并且永远不会回归,这势必会影响内存驱逐机制,具体确定要衰减的方法:
衰减值:
- 距离上一次衰减分钟数 = 当前时间 - 最近衰减时间
- 衰减值 = 距离上一次衰减分钟数 / lfu_decay_time
其中控制衰减周期的参数:
lfu_decay_time,单位为分钟。可见,如果要让key衰减的快点,可以把lfu_decay_time设置的小点。
Redis将这24位分成两部分,最高两个字节用于存储衰减时间,最低一个字节用于存储访问计数器。
1 | +----------------+----------------+----------------+ |
只有8bit来存储访问次数,所以里面存储的并不是精确数据,而是一个大概的数据。
下面是计数器增加的关键代码:
1 | /* Logarithmically increment a counter. The greater is the current counter value |
可以看出,随着计数器越来越大,计数器增加的概率越来越小。
为什么没有设置过期时间的key被删除了?
使用了allkeys策略,导致对所有范围内的key进行淘汰。

